RL-ViGen: A Reinforcement Learning Benchmark for Visual Generalization
RL-ViGen: A Reinforcement Learning Benchmark for Visual Generalization
Zhecheng Yuan*,
Sizhe Yang*,
Pu Hua,
Can Chang,
|
Abstract
Visual Reinforcement Learning (Visual RL), coupling with high-dimensional observations, has consistently confronted the long-standing challenge of generalization. Despite the focus on algorithms aimed at resolving visual generalization problems, we argue that the devil is in the existing benchmarks as they are restricted to isolated tasks and generalization categories, undermining a comprehensive evaluation of agents' visual generalization capabilities. To bridge this gap, we introduce RL-ViGen: a novel Reinforcement Learning Benchmark for Visual Generalization, which contains diverse tasks and a wide spectrum of generalization classes, thereby facilitating the derivation of more reliable conclusions. Furthermore, RL-ViGen incorporates the latest generalization visual RL algorithms into a unified framework, under which the experiment results indicate that no single existing algorithm has prevailed universally across tasks. Our aspiration is that RL-ViGen will serve as a catalyst in this field, laying a foundation for the future creation of universal visual generalization RL agents suitable for real-world scenarios. Access to our code and implemented algorithms is provided at https://github.com/gemcollector/RL-ViGen.
Task Categories
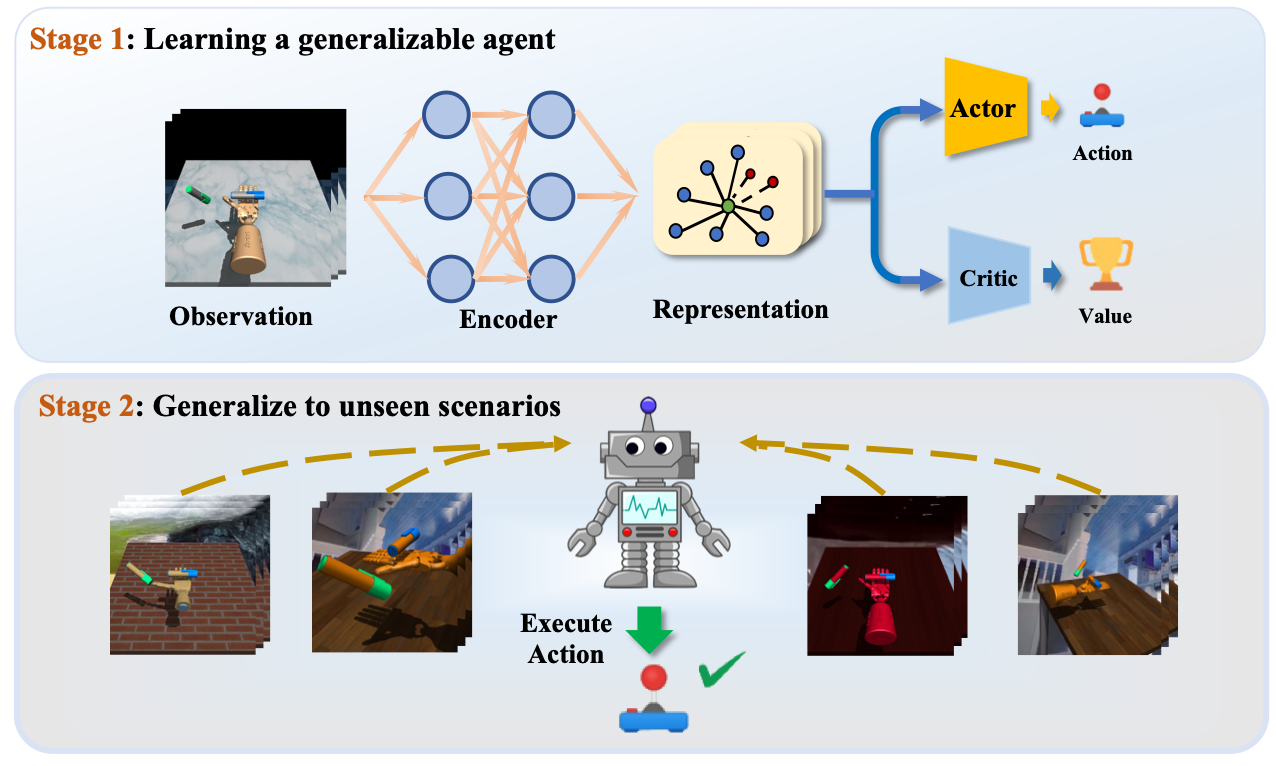
RL-ViGen consists of 5 distinct task categories, spanning locomotion, table-top manipulation, autonomous driving, indoor navigation, and dexterous hand manipulation. In contrast to prior benchmarks, RL-ViGen employs a diverse array of task types for evaluating the agent's generalization performance.
CARLA serves as a realistic and high-fidelity simulator for autonomous driving. RL-ViGen provides an enhanced range of dynamic weather, and more complex road conditions in different scene structures. Furthermore, flexible camera angle adjustments are also integrated.
Adroit consists of a sophisticated environment which tailored for the dexterous hand manipulation tasks. In RL-ViGen, we have enriched the Adroit environment by incorporating diverse visual appearances, camera perspectives, hand types, lighting changes and object shapes.


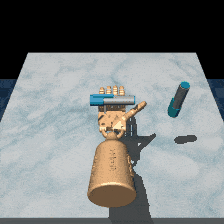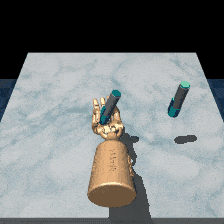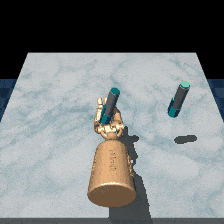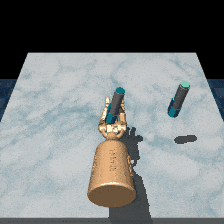
Robosuite is a modular simulation platform designed to support robot learning. RL-ViGen incorporates dynamic backgrounds and adaptive lighting conditions, refining the simulation to be closer to the real world.



As an efficient and photorealistic 3D simulation, Habitat combines numerous visual navigation tasks. RL-ViGen proposes additional scenarios with different visual and lighting settings.



DeepMind Control is a popular continuous visual RL benchmark. RL-ViGen introduces objects and corresponding tasks from real-world advanced locomotion and manipulation applications, such as Unitree quadrupedal robots and Franka Arm.
Training Scenes
For better understanding the difference between the novel scenarios and the original training environments, we show the training scenes of each environment in our paper. Meanwhile, you can also choose any environment as your training scenarios.
Door
Lift
TwoArm Peginhole
Door
Hammer
Pen
Unitree Stand
Unitree Walk
Anymal Stand
Navigation
Driving
Generalizaton Categories
Our benchmark offers a wide range of generalization categories, including visual appearances, camera views, variations in lighting conditions, scene structures, and cross embodiments settings, thereby providing a thorough evaluation of algorithms' robustness and generalization abilities.
In RL-ViGen, different components within the environment can be modified with a wide range of colors. Meanwhile, the dynamic video background is also introduced in challenging setting.


Lighting changes is an inevitable occurrence in the real world. Therefore, in order to enable agents to adapt to lighting variations, we provide some interfaces related to lighting, such as altering light intensity, colors, and dynamic shadow changes.


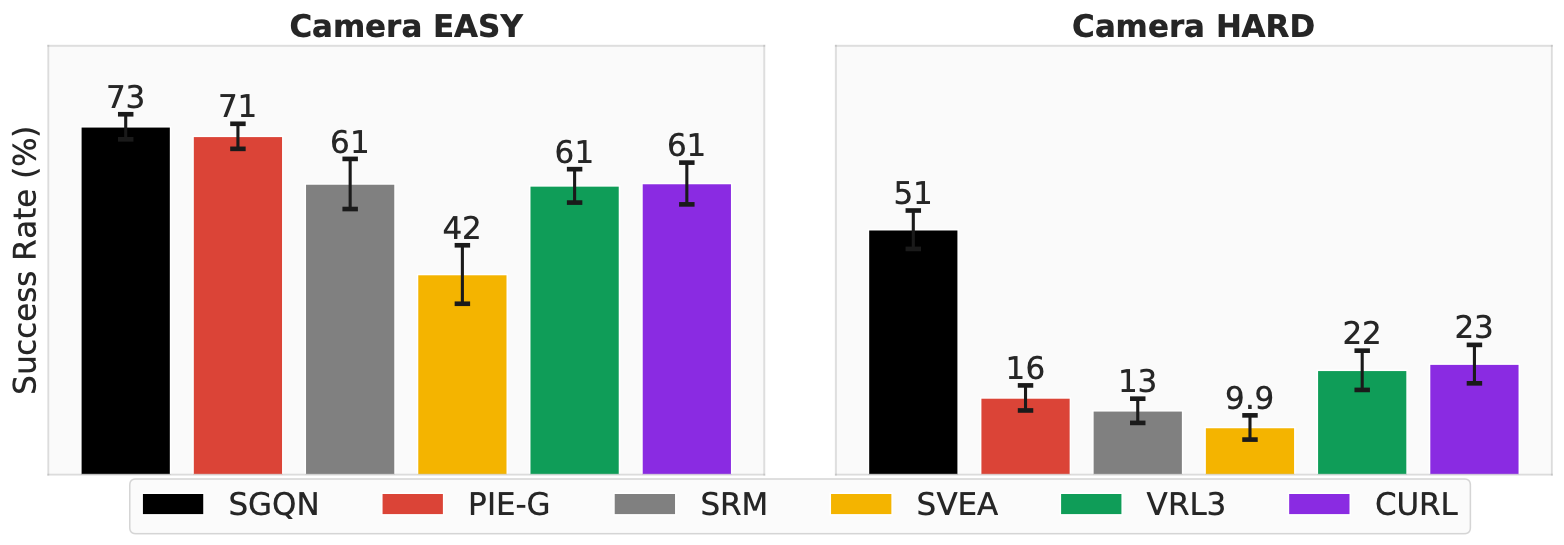
In the real world, the agents have to encounter varied camera configurations, angles, or positions that may deviate from those experienced during training. We offer the access to set the cameras in different angles and distances. In addition, the number of cameras can be adjusted accordingly.


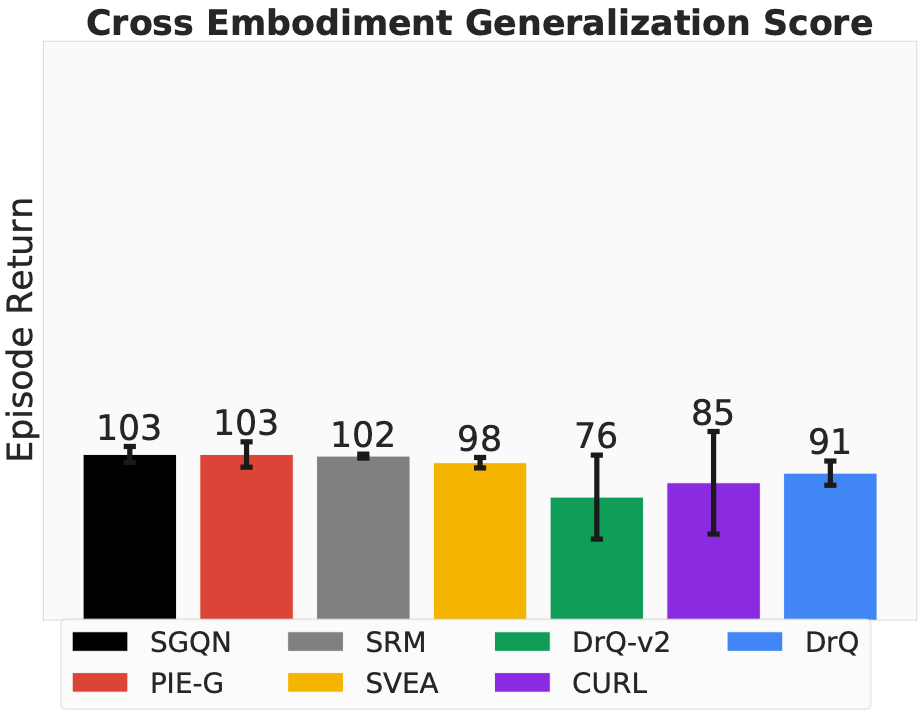
Adapting learned skills and knowledge to different physical bodies or embodiments is essential for an agent to perform well across various platforms. Our benchmark also provides access to modify the embodiment of trained agents in aspect of model types, sizes, and other physical properties.


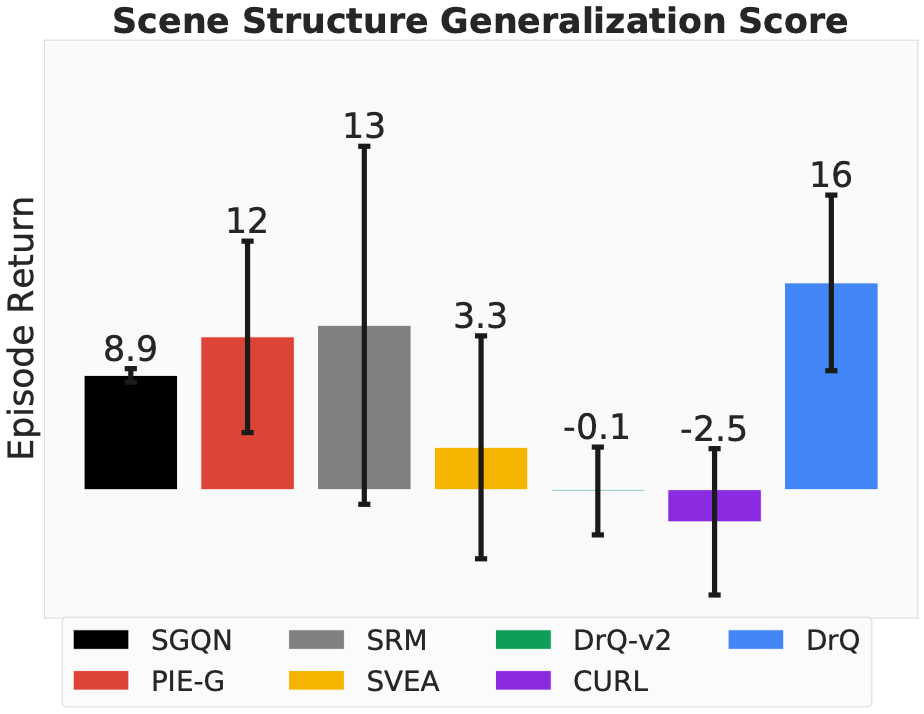
Mastering the ability of understanding and adapting to different spatial arrangements and organization patterns within various scenes is crucial for a generalizable agent. Our benchmark enables modifications in scene structure by adjusting maps, patterns, or introducing extra objects.